
AI’s Next Battleground: The Edge
Also… WTF is The Edge??

[Human editor’s note: I’m doing an experiment with this one. I’ve been working on a slide deck to help convey some of my AI infra theses during live discussions with bankers and investors. You can see that deck here. So my experiment is that I told ChatGPT to look at that deck and write a post re my evolving thesis about AI at the edge using the snarky tone in my previous posts. With some polishing and [human editor’s notes] and AI-generated (and suggested) images and leaving in most of the em dashes, this is what it came up with. Whatdya think?]
With CoreWeave public [along with long time pals Nvidia and everybody around and in between], everyone’s watching the AI arms race play out in, well, public: new models, more parameters, bigger clusters, flashier launches[, and, of course, IPOs]. The spotlight has been on training, and for good reason—it’s foundational, expensive, and still scaling like crazy. But while training remains massive and gets more massive[r], inference is already bigger; and, growing bigger[er].
Inference is where the model meets the user; i.e., it’s the model in production answering requests / creating content / writing code. And sometimes, this is where the model promptly forgets your name, ignores your request, and suggests something completely unhinged. [Hallucinating was hip in the 70s; now… not so much.] Still, that’s where the next wave of infrastructure battles—and value creation—is headed. And increasingly, it’s happening not (only) in the [core GPU] cloud, but at the edge.

Training got us here [so far]. [Does] inference get us paid [more]?
Let’s not bury the lede: training models is still a big deal. According to SemiAnalysis [and ChatGPT], model training spend hit $25B+ in 2023. [Human editor’s note: that link is dead, but SemiAnalysis is amazing; recommend. Also, I can’t find that 2023 number - but it’s a big number; and fwiw ChatGPT, when questioned, conceded: “various estimates peg 2023 training infra spend between $15B–$25B, depending on what you include (e.g. chip capex vs. cloud services vs. model dev).] Nvidia’s enterprise line keeps humming. And as new foundation models continue to emerge, this spend will keep climbing.
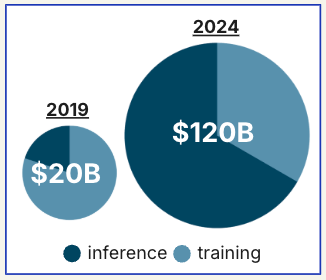
But inference? That’s already outpacing training. Nvidia, on a recent earnings call [according to ChatGPT], mentioned that over 60% of datacenter revenue is now inference. [Human: fwiw, I’ve found numbers that suggest it’s at least 40% so this may not be too far off.] And Omdia projects inference workloads will outpace training by a factor of 4x by 2026. [Human: I don’t know Omdia and that link, again, doesn’t work, but this should be, at the very least, directionally accurate. Also, hey ChatGPT, work on your links, eh?]
Why? Because inference isn’t a one-time event. It happens every time someone types a prompt, completes a checkout flow, or opens an AI-enhanced app. It’s the runtime layer. The everyday engine.
Inference is moving to[ward] the edge…
…because inference is often:
Latency-sensitive (users won’t wait).
Cost-sensitive (each query hits your wallet).
Personalization-sensitive (context lives locally).
That combo starts to make edge deployment not just viable—but [maybe] preferable [sometimes]. Cloud GPUs are still critical—but they’re not always optimal. They’re like renting a private jet to deliver a pizza. Fast? Sure. Worth it? Not unless you’re OpenAI on a [code] bender. If you’re running high-frequency inference across millions of users, network latency and egress costs pile up fast. And not every inference needs a monster model or the full might of a hyperscaler. Sometimes you just need a decent answer quickly and cheaply.
So inference will go [more] local—out of the cloud and into CDNs, telco edge nodes, even smart devices.
But… is the edge actually cheaper and faster?

Let’s say your app runs 1 million queries/day:
In the cloud: $1,000–$10,000/month
At the edge: $100–$1,000/month
That’s a 10x cost swing, not including sneaky egress charges. [NB: For lighter models and basic inference (think autocomplete, tagging, or ranking), edge costs can run as low as $100–$1,000/month. More complex, high-volume, streaming workloads — especially those with larger models — can push edge inference toward $150K+ monthly. (See my deck draft for those cases.)]
Now latency:
Cloud inference often runs 200–400ms, including the network round-trip.
At the edge, you can get 30–50ms, and even under 10ms with caching.
In practice, total edge latency (including cold starts and TTFT) can range 25–200ms, while cloud inference can stretch past 1 second depending on model size and spin-up. But for warm-start lightweight models, edge inference often runs 5–50ms — and costs 10x less. That’s not just user-experience nice-to-have—it’s abandonment prevention.
“But latency is mostly compute—so does the edge even help?”
This pushback is real—and [at least] half true [for now]. If you’re running GPT-4 (>1T parameters) or LLaMA 70B (~100B parameters)? Yes, the compute is the bottleneck. Moving it to the edge won’t help much—and it won’t fit. But many real-world use cases don’t need frontier models.
If you’re auto-tagging images, running a voice assistant, offering real-time text suggestions, personalizing product listings… your model is probably 2B–7B parameters, and total inference time might only be 50–150ms. In those cases, network latency is often 30–70ms round trip so moving to the edge can halve response times–and skipping the trip to Oregon shaves dollars too.
It’s not that the math disappears. It’s that the math starts sooner, happens closer, and skips the Uber [X Share] ride to the GPU warehouse.
The edge is a mess—and [maybe] a goldmine.
The cloud AI stack is consolidating fast. The edge stack? Still chaos. There’s no standard toolchain, no clear dominant player, no consensus on model formats or runtimes. And that ambiguity is where opportunity lives. Because what is emerging is a new stack:
Tiny models: quantized, distilled, and fast.
New runtimes: Mojo, MLC, GGML, TVM, Wasm.
Cheaper [er, more efficient?] chips: from Groq, Tenstorrent, and beyond.
Who Wins? Hell if I know. [Or maybe I’m just not telling….🤔] Figuring that out is the fun part. Some familiar faces are circling:
CDNs like Cloudflare, Fastly, & Akamai [may] suddenly have beachfront property.
New chipmakers like Groq are optimizing for deterministic edge inference.
Infra players are racing to build the compilers, runtimes, and delivery systems.
Telcos are remembering they exist.

But there’s no AWS of edge inference. Yet. [Pipe down, Cloudflare, you’re heading in the right direction.] But if you’re squinting at networks with low-latency real estate and wondering who gets re-rated first—you’re not alone. Some of them may not even know what they’re sitting on.
How to play it? [Spoiler alert: carefully.]
If you’re thinking like an operator or investor, this isn’t just a tech shift—it’s a filter. Look for:
Under-monetized infrastructure sitting close to users.
Infra companies with programmable points of presence.
Vendors quietly swapping GPU clusters for lighter, faster inference.
Platforms where small models can run fast, and often, and cheap.
Let’s just say there’s more than one player where a smart acquisition—or the right SDK rollout—could change the game entirely. You probably won’t hear about it on CNBC [yet]. But someone’s getting a steal.
[Almost] final thought from the Porch….
Most people still think the AI wars are being fought inside data centers. And right now, they are. But the next battles—the messy, high-margin, power-efficient ones—may be fought at the edge. They won’t be won by whoever trains the biggest model. They’ll be won by whoever serves the smallest ones fast, cheap, and everywhere. So bring a compiler, a caching strategy, [a bundle of ASICs,] and maybe don’t shout too loud if you’ve already bought your spot…. See you at, well, the edge.
[Oh, and almost forgot…. If you’re wondering: “WTF is the edge?” You’re not alone. So what is it? I don’t know exactly and I’ve had my own issues with technology definitions - see my post titled: “Defining Web3 (Without Self Mutilation).” But I’m going to describe it here as almost any node / location / device where a model can sit that isn’t the core GPU data center. That’s my own definition and understanding based on reading everything that the edge isn’t.
Fwiw, ChatGPT defines it as “computing devices that are physically close to where data is generated or where actions are taken, rather than relying on distant cloud servers or centralized data centers.” What about CDNs? “Content distribution networks are a stepping stone to the edge, and they can play a key role in AI at the edge, but they’re not exactly the same thing.” Meh, for the sake of this post they’re kinda the same, even though they’re not.]
