


F*** Chips. Ship tokens.
Upstart AI chip companies are selling INFaaS instead of silicon — is this the way around the CUDA moat?

You know what’s harder than building a better chip? Convincing developers to use it. That’s why Groq, Cerebras, d-Matrix, Etched, tenstorrent, and a growing crew of AI hardware startups aren’t selling chips — they’re selling tokens. Their strategy: skip the CUDA moat entirely by running their own infra and delivering inference-as-a-service (INFaaS). No drivers. No compilers. No “just clone this repo and pray.” Just tokens in, answers out. Fast. Cheap. Scalable. Nvidia’s not dead (I still own the stock), but this might be the first real end-run around their grip on developer mindshare. Here’s why….

Everybody talks about the CUDA moat. (Trust me, Google it.) And they should. It’s deep. Here’s a more detailed description of CUDA for those that don’t (pretend to) fiddle around with GPUs; TLDR: it’s a proprietary software platform for programming (Nvidia) GPUs. Every engineer knows it and not a single engineer wants to learn another one. (It’s also quite powerful… for Nvidia chips.) So aside from making the best chips in the market, Nvidia has solidified its gargantuan market share (dare I say near monopoly?) by leveraging its (CUDA) software. Using other chips, even ostensibly faster / better ones, is off the table for most because they don’t want the hassle of learning how to make them work well. Yada yada yada, Nvidia is worth $3T; and other chip companies… aren’t.

The rainbow bridge across the CUDA moat has been under construction by competitors and upstarts for years. AMD has its own (open source) ROCm platform that’s making progress, albeit clunky and slow. Compilers and inference engines like Together AI and Fireworks AI help abstract some of the mess. But programming GPUs is a pain in the ass. It’s why CUDA and kernel and performance engineers are in high demand (and there aren’t that many so they’re, well, costly). It’s also why Mako (disclosure: I am an advisor / equity holder) developed their optimization platform and a large language model that writes kernels all by itself.
It’s also why I’ve been skeptical of every new chip company claiming to best Nvidia’s performance. The question remained: “So what?” Because these new chips could be fast af, but if it’s a hassle to use them then nobody will.
Enter: a “new” semiconductor model.
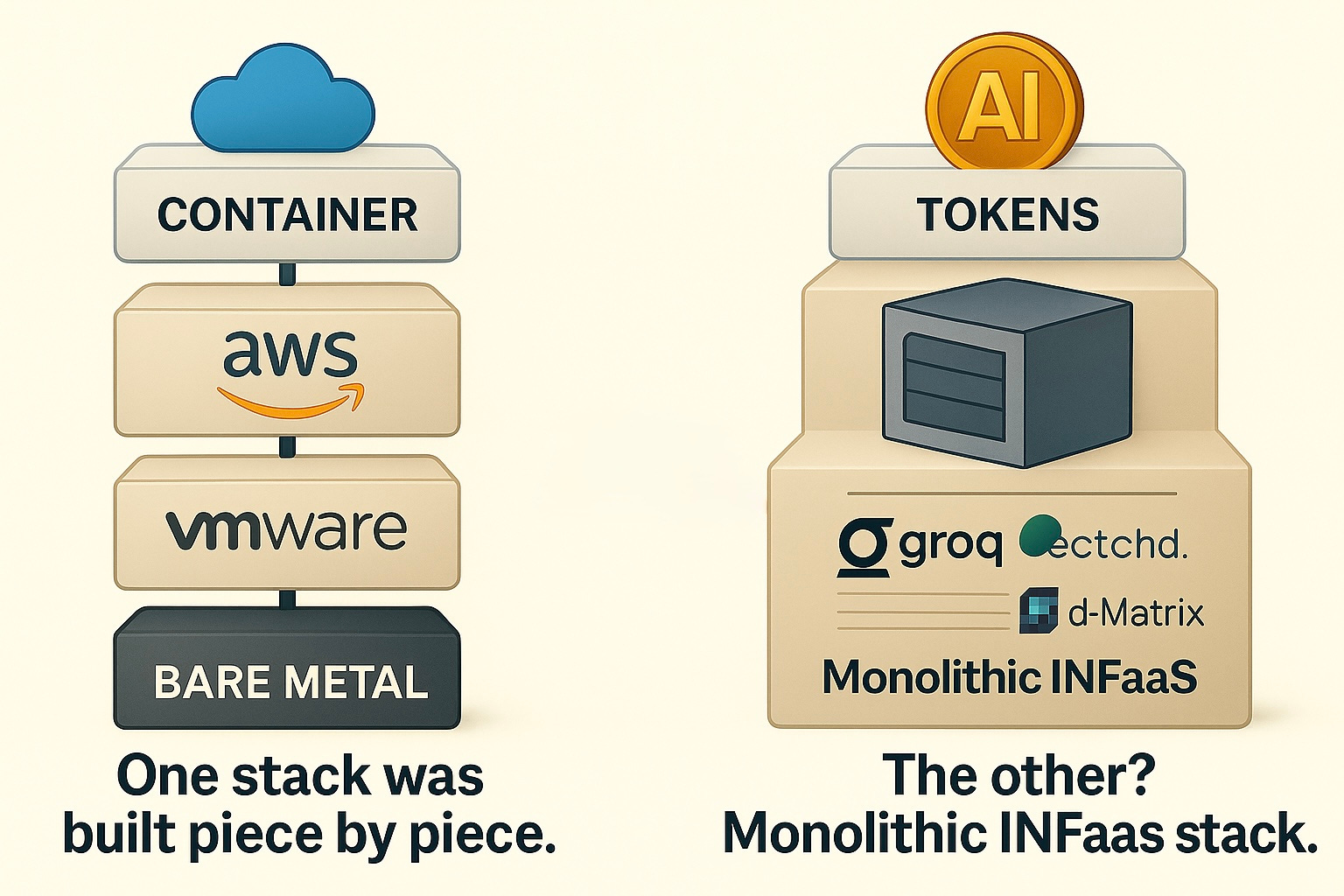
If it’s such a royal pain in the ass to cross the CUDA moat then how about skipping it altogether? That’s precisely what upstarts like Groq, Cerebras, d-Matrix, tenstorrent, and etched are doing. Rather than selling their chips, they’re spinning up their own AI data centers and selling access — not silicon. Specifically, they sell tokens, or inference as a service (or IaaS, not to be confused with infrastructure as a service, or, um, IaaS - so let’s call it INFaaS, shall we?) Just like AWS doesn’t sell servers (they sell compute in $/hour), these NKOTB sell blazing-fast, token-priced inference endpoints in $/token, not $/chip (or $/hour).

Groq, for example, didn’t say, “Here’s a better GPU.” They said, “Here’s a token API. It’s blazing fast. You don’t need to know what’s under the hood.” You don’t batch, warm, or wait. You just send tokens and get tokens back. No drivers or compilers and, of course, no CUDA. Just speed. They’ve gone full Stripe-for-inference — clean docs, fast onboarding, token-metered billing. In doing so, they turned their chip into a backend detail. Not a product, a service. Not silicon, software. That’s the move.
Groq isn’t alone. Companies like Cerebras, etched, SambaNova, d-Matrix, and tenstorrent have different approaches to chip design, but the same strategy: control the infra, abstract the hardware, and sell the output.

Because (maybe) developers don’t want a new chip. Maybe they want a faster endpoint where cost follows usage; token-metered services mean no overprovisioning or idle GPU bills. (One study showed that a third of GPU users achieve <15% utilization; rough economics for the most expensive unit of compute.)
INFaaS can let them skip the whole CUDA migration headache (for popular models) because once the developer hits that API and gets a blazing-fast response, they don’t care about the compiler flags. They’re not porting PyTorch and kernels. They’re building product. And that’s (always) been the goal: building cool stuff.
Every layer of digital infrastructure gets abstracted eventually. VMware / hypervisors abstracted servers and enabled cloud services. Docker abstracted cloud provisioning with containers. Now AI inference is going the same way. From silicon… to service. That’s the move.
Is Nvidia in trouble? Nope. And / but they’ve already made plenty of moves to adapt to this emerging model. They’ve all but outsourced cloud scale to CoreWeave (which, disclosure: I still own) and other GPU neoclouds, bundled hardware into full-stack DGX systems, and bought / quietly rolled out Lepton with a user friendly UI / UX to reduce inference latency on their own terms. They see the shift and they’re hedging accordingly.
They’re not alone. Google’s been playing this game for years with TPUs—offering inference endpoints that abstract the hardware entirely. The difference now is that startups are doing it too, and faster. (Fun fact: Jonathan Ross, who kicked off Google’s TPU effort, is the founder and CEO of Groq; h/t Jacob Loewenstein ;-))
Is an AI CDN “What Comes Next?”?
Last month I wrote here that ChatGPT’s pulsing black dot is the new universal symbol of digital dread and that “AI CDNs” might be the solution: distributed networks of low-latency inference end points.
Paul Graham posted a similar complaint (also last month on a social platform who shall not be named): ChatGPT is so slow that he sometimes switches to Google while waiting for it to respond. Demand is huge. But dialup-era drag is a modern AI application churn risk.
Some use cases already critically need low latency (e.g., AI voice bots agents, streaming AI apps). But as more apps go real-time, the pressure for fast, distributed inference (as a service) will only grow.

Perhaps that time has come (already) for distributed inference endpoints optimized for latency, load, and geography powered by whatever hardware wins. Doesn’t matter if it’s Nvidia, AMD, Groq, Cerebras, or an ASIC no one’s heard of yet (or Intel, but let’s face it - it’s probably not Intel). What matters is:
How fast does it get me tokens? And…
How much does it cost to serve them at scale?
Because in this new world, chips are still cool, but tokens are the product.

Food for thought:
Should Akamai (AKAM) or Cloudflare (NET) or another large CDN provider buy a chip acceleration company to make their own AI CDN?
Should a chip company (upstart or mature) build its own CDN or buy one like Fastly (FSLY)?
Are AWS and Nvdia evolving into a collision course to become vertically integrated chip makers with their own data centers selling INFaaS? (Spoiler alert: yeah.)
Is anybody doing this already? Cloudflare or someone else? Hit me if you know.

Extra credit / homework:
Share this post with 3+ other people and via your social networks (please).
Send an email to me at dslevy [at] gmail [dot] com with:
A note about who you are and what you’re all about and how you found this blog post.
One good idea about how to leverage the theme in this post; e.g., an investment idea — public or private, an M&A transaction, startup idea (that I promise not to steal), point / counterpoint, etc.
The names of the people with whom you shared the post and links to your shares on social media.
What the image directly on top of this section is and why I put it here.
I will send a “Fuck Chips / Ship Tokens” tshirt to the first few people that do this while supplies last; i.e., until I don’t want to pay for it anymore. (I will get your size and address etc. in our email exchange.)

