
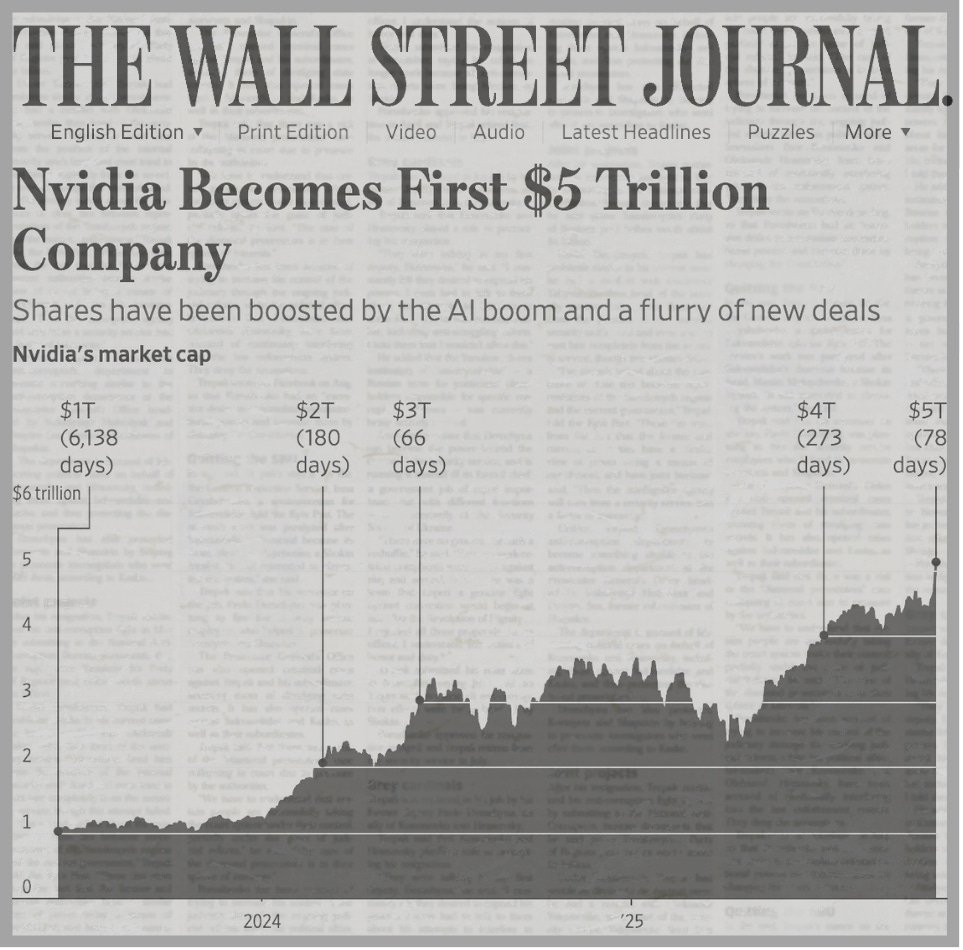
$NVDA5T
How my $4,500 joke turned into a $5 trillion punchline.


Nvidia just became the world’s first $5 trillion company. That was a headline in October 29th’s Wall Street Journal alert; and also the punchline to a joke I wrote 17 months ago.
TL;DR: I wrote a ridiculous $NVDA target, the world GPU-ified anyway, the math bent reality, substations melted, and this is the part where I pretend it was obvious the whole time.
In May 2024, I published The Bull(*) Case for NVDA $4,500/share. It was part analysis, part self-aware hype (hence the asterisk). The stock was flirting with $1,000 then (pre-split so $100 now), and I argued it could quadruple again because the world was about to GPU-ify everything.
On October 29th, 2025, the stock closed ~$207 (so ~$2,070 pre-split) — valuing Nvidia at roughly half of the insane $10T valuation I floated back then. So no, I didn’t get it exactly right. But being off by a factor of two in this business is basically bullseye territory.
Call this a self-deprecating victory lap (emphasis on deprecating). But I’m not writing this just to say “I told you so.” (That’s at least partially a lie.) I’m writing it because the same forces that made Nvidia a $5T behemoth are already pushing datacenters to edges, training to inference, and physics to narrative. The question now isn’t which GPUs won (Nvidia’s did), but which chips, clouds, networks, and tools shape what comes next — the ones that can actually make all this compute useful, efficient, agentic (sorry), and everywhere.
🐂 How the bull got its horns.
In 2023 and 2024 I made three points that were either prescient, obvious, or lucky (take your pick):
The GPU:CPU attach rate (then ~10% according to my questionable math and statistics) would climb toward 100%.
The software stack would collapse into a single “logic layer,” sitting on GPU-like hardware.
Nvidia would (still) own that layer via CUDA, NIMs, and whatever alphabet soup Jensen cooked up next.
All of which sounded slightly ridiculous in 2024, right before everybody started running (far more) training and inference workloads.
📉 The Middle Part (aka the forgotten mini crash).
Things went sideways fast after my initial call.
January 21, 2025: OpenAI (and friends) announced the Stargate Project at the White House — a “$500 billion” AI infrastructure build flanked by the brand-new / still-smells-like-2016 President / DIT (dictator in training), depending upon your feed. The builds were already happening, of course, but never let a good press conference get in the way of a MAGA photo op (server racks optional).

Days later (though actually on the same day just for some reason it took a week to sink in), DeepSeek AI released its R1 model showing LLM-level performance at a fraction of the cost. Suddenly the narrative flipped from “GPU demand forever” to “maybe we don’t need that many monster GPUs after all.” Markets reacted like someone had just invented free GPU compute.
NVDA dropped roughly 20-25% from its January high.
AMD and Super Micro each slid similar double-digit chunks.
The entire AI-infra trade took a breather that felt like a crash.
And CoreWeave’s (March) IPO — the crown jewel of the GPU-cloud story — got sized down, priced soft, and broke issue.
That was my oh-shit moment — the part where you wonder if your beautiful attach-rate thesis just blew up on launch (and if your beautiful undergarments just turned a darker shade of brown). So I did the adult thing: I re-read my own notes, changed my underwear, and published a piece titled “$CRWV IPO: The AI Trade Just Got Cheaper.” I basically said, “Okay, the IPO broke, which means it’s time to double down.” (To be fair, had I actually put my money where my proverbial mouth and blog were, my current CoreWeave trade would be worth a lot more, but I’ll take what I’ve got).

And sure enough, as the panic subsided, the builders kept building. Inference demand didn’t die; it flourished. The same logic I started with came roaring back: GPUs power the logic layer; the logic layer powers everything else. (Also, the world was briefly re-introduced to Jevons Paradox, the Victorian notion that efficiency drives more consumption. Everyone wrote a post about it. I’m glad I didn’t.)
TL;DR: I got scared, shit my pants, the math started working again, and then my conviction returned (along with a clean pair of boxer briefs). The thesis didn’t die — it just paused for a moment.
What actually happened.
Attach rate: Hyperscaler and enterprise inference workloads went vertical. Between training, fine-tuning, and edge LLMs, GPUs and accelerators now drive most of the growth in data-center capex (40-60% of new spending by most estimates). The old world of one GPU for every ten CPUs changed to one for every two to five (depending upon how you count).
NIMs (Nvidia Inference Microservices): Nvidia quietly rolled them out everywhere. They’re not sexy, but they make it trivial to drop an “LLM-style interface” in front of any database or app. Suddenly every dataset, document, or file becomes a living thing that you can talk to, build with, and iterate on instead of just reading or querying.
Ecosystem lock-in: CUDA is stickier than ever. Every serious framework still compiles to Nvidia first. AMD’s made progress with MI300 (and forthcoming MI X00s), but it’s fighting inertia more than performance gaps.
So yes — some of the logic-layer collapse is real. It just didn’t all happen on my schedule (or in my brokerage account).
The attach-rate thing (a.k.a. I swear I had a source… somewhere).
Back in June 2023 I tossed out a stat about 400 million CPUs vs 40 million GPUs per year — and yes, I actually found that somewhere. It came from Mercury Research, which counted ~471M x86 CPUs shipped in 2021 and ~374M in 2022 — basically the entire global CPU universe (desktops, notebooks, servers). My brain paired that with roughly 40M discrete GPUs (a mix of desktop boards and data-center cards) and voilà: a catchy 10 percent “attach rate.”
Turns out it was accurate math applied to the wrong denominator — apples to motherboards. The fairer comparisons would’ve been:
Client side (PCs): ~260M PC CPUs vs ~35-40M discrete GPUs = ~15% (roughly one add-in card per six PCs).
Data center: ~20M server CPUs vs ~3-4M data-center GPUs = ~15-20% percent (about one accelerator per five CPUs).

Fast-forward to today:
PC GPU attach (counting integrated + discrete) now averages >100 percent.
In AI servers, analysts estimate ~1 GPU for every 2–3 CPUs, ~2x 2022 levels.
The global compute mix is tilting toward accelerators; the gap shrinks every quarter.
So yes — my “10 percent attach rate” was technically a mis-sized fraction, but directionally dead on. The only thing I underestimated was how quickly the world would start acting like every CPU needs a sidekick. (FWIW, I’ve conceded in several pieces that I often make up the math; also, I sometimes just get it wrong — so consider this your friendly disclaimer about my ineptitude when following my missives.)
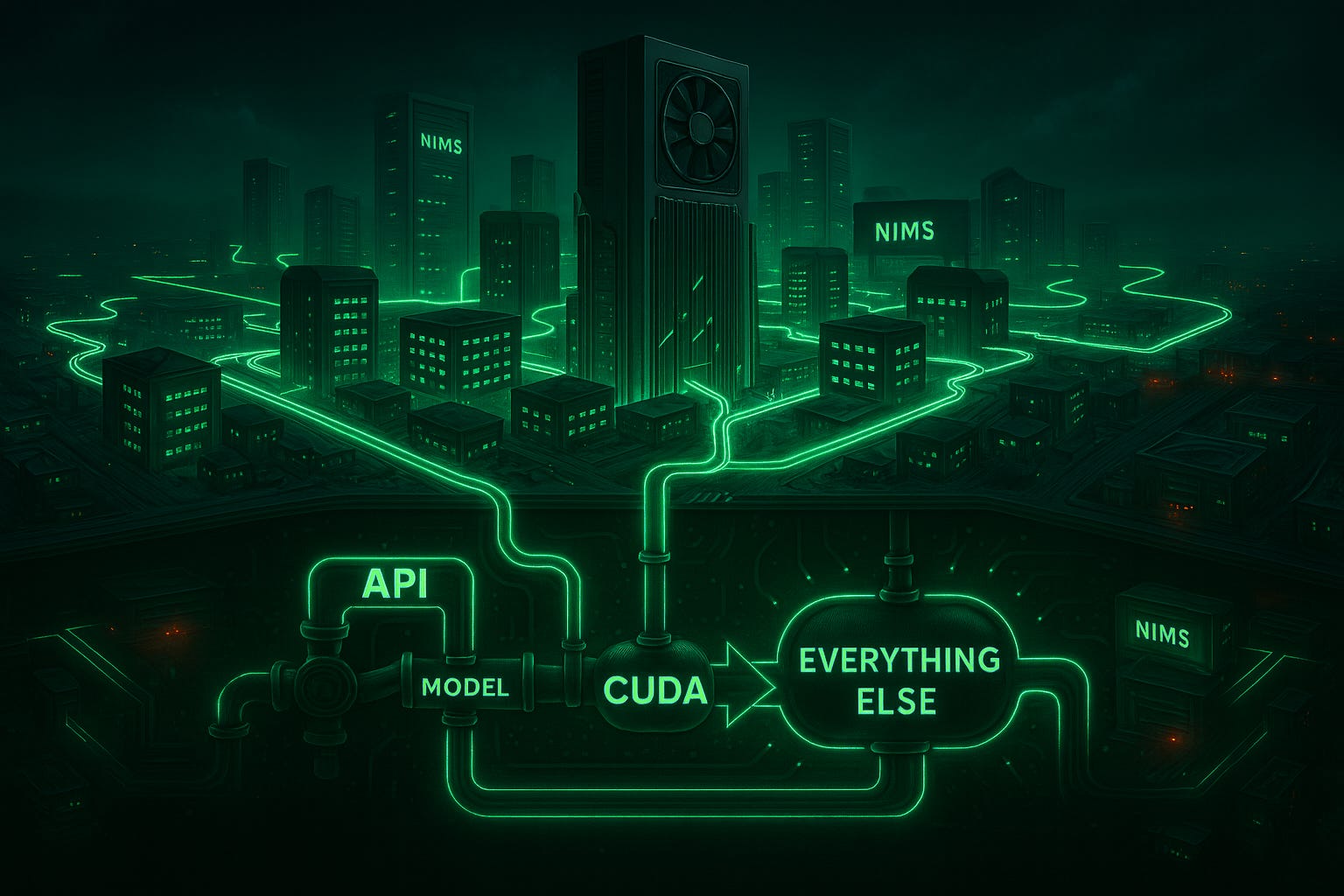
The logic layer really did start collapsing.
When I wrote about the “single logic layer,” it sounded like futurist hand-waving. Now it’s simply how developers build: they call an API that calls a model that calls everything else. AI isn’t a product anymore; it’s plumbing and that plumbing mostly runs on Nvidia. For now.
The hard limits of scale.
Infrastructure physics: GPUs demand massive power-feeds, cooling, substations and grid build-out. (They don’t just plug in.) Datacenters are set to double their electricity draw by 2030 (to ~945 TWh globally, according to IEA and others including, um, ChatGPT); and one large AI cluster may consume hundreds of megawatts (roughly the output of a small nuclear reactor). The average substation is 20-50 MW, so you’re not just adding servers; you’re adding power plants and substations. And you really can’t retrofit the planet with GPUs without melting a few substations.

Elastic economics: Per-inference costs have been dropping rapidly thanks to better hardware, compression, and model engineering. At the same time, demand (token volume, inference queries, deployment scale) is surging — creating the illusion that TAM is growing faster (or slower?) than it is.The broad truth: the unit cost curve is bending downward even as the market curve is bending upward.
Competition: Nvidia still dominates the GPU/datacenter world by a wide margin, but the crown isn’t eternal. Between AMD’s MI-series, custom-ASIC efforts, and edge-inference platforms, the market is quietly opening up. (One engineer at Nvidia told me: “I’m actually surprised we’re doing this well in inference.” Or something like that.) The GPU throne remains Nvidia’s, but the challengers are gathering at the gate.

If there’s a law of AI investing, it’s this: by the time the narrative makes sense, the margins start changing.
What comes next….
The next wave isn’t training — it’s inference distribution. (That. Does. Not. Mean. Training. Is. Going. Away.)
As models distribute to the edge, latency beats throughput, and whoever owns those nodes wins.
Nvidia will chase that too, but the architecture will fragment. (That. Does. Not. Mean. Nvidia. Is. Going. Away.)
If my first piece was about GPUs swallowing CPUs, the sequel is about where those GPUs (and accelerators) end up. Spoiler: not just in data centers.

So, was I right?
Sort of. Accidentally. Eventually. If you wait long enough, even your bad timing ages into foresight. The thesis is working. And the price target (now $450)...? Well, with enough AI agents blowing bubbles, anything’s possible.
I’ve been wrong plenty (see my piece on DigitalOcean from this week). But sometimes I get lucky; and sometimes the bull’s just standing in the right pasture.
I’m still long NVDA. I still don’t own enough. (Full transparency, I’ve trimmed some for portfolio management and concentration mitigation; and to buy some shares in private companies; and, well, for paying bills.) And, as always, I’m still a little full of (bull)shit.
