
The Layer Everyone Skips.
The Nebius-Eigen acquisition is a map.

Last week, Nebius announced its $643M acquisition of Eigen AI to build a “frontier inference platform.” Headline, eyebrows, NBIS pops ~$40/share (+27%), move on. Another AI infra deal. Except it isn’t. And skipping it is a mistake.

Not (yet) a model company. Not (just) a cloud provider. (Sounds like a Britney Spears song. You’re humming it right now. Don’t lie.) Something aimed squarely at the act of running models in production, which is where the economics live. That framing matters more than the transaction itself, and it explains a pattern that’s been quietly compounding across the market.
What skipping this layer costs investors.
The popular narratives cluster(!) around models and APIs because they’re easy to see and easy to measure. OpenAI releases something, everyone writes about it. Anthropic announces a feature and entire stock universes get clobbered.
Meanwhile, there’s a whole layer of the stack that doesn’t announce itself loudly — and it’s where a growing number of real businesses are building.
On a call with Jim Fish from Piper Sandler and a dozen or so institutional investors last week, one of the recurring questions was: who exactly does DigitalOcean serve in an AI world? The confusion was genuine. (If I’m being honest, I struggled with it too.) The answer lives in this middle tier — which is exactly why it gets missed. And if you’re asking the question, you’re probably underweighting it.
The companies operating here mostly leave training to someone else and run models continuously, at scale, and in production. The difference between doing that well and doing it badly is increasingly the difference between a business with defensible margins and one quietly leaking money into a GPU somewhere.

That’s what skipping this layer costs: actual dollars. (Not a missed trend.)
Three tiers. One underappreciated middle.
Here’s how companies are actually using AI today.
API users: teams building on OpenAI and Anthropic. This is what you hear about most. It’s the fastest path from zero to working. No infrastructure, no capacity planning, no late-night GPU therapy sessions. Totally valid until usage gets predictable and the per-call economics start to sting.
Bare (or mostly bare) metal users: the model builders and large-scale operators (like, well, OpenAI and Anthropic) running training and fine-tuning on CoreWeave, AWS, and similar. Different problem set. Much bigger capital intensity.
In between: a big, underappreciated chunk of the market — companies running their own models and forks of open models as a core part of their product and workflows. Customer support pipelines, document processing, internal copilots, agent systems calling other systems. The kind of thing that quietly becomes a real line item.
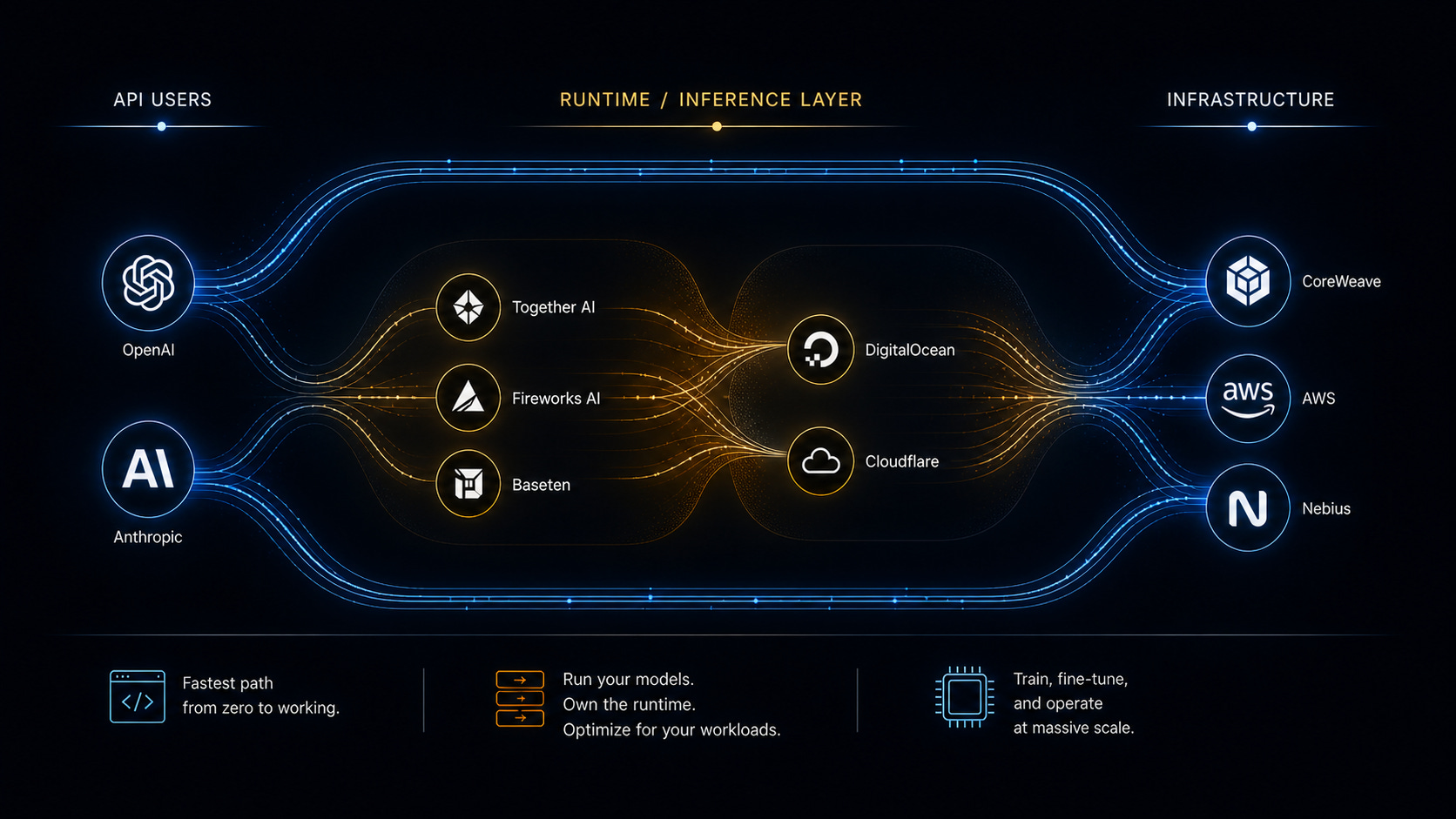
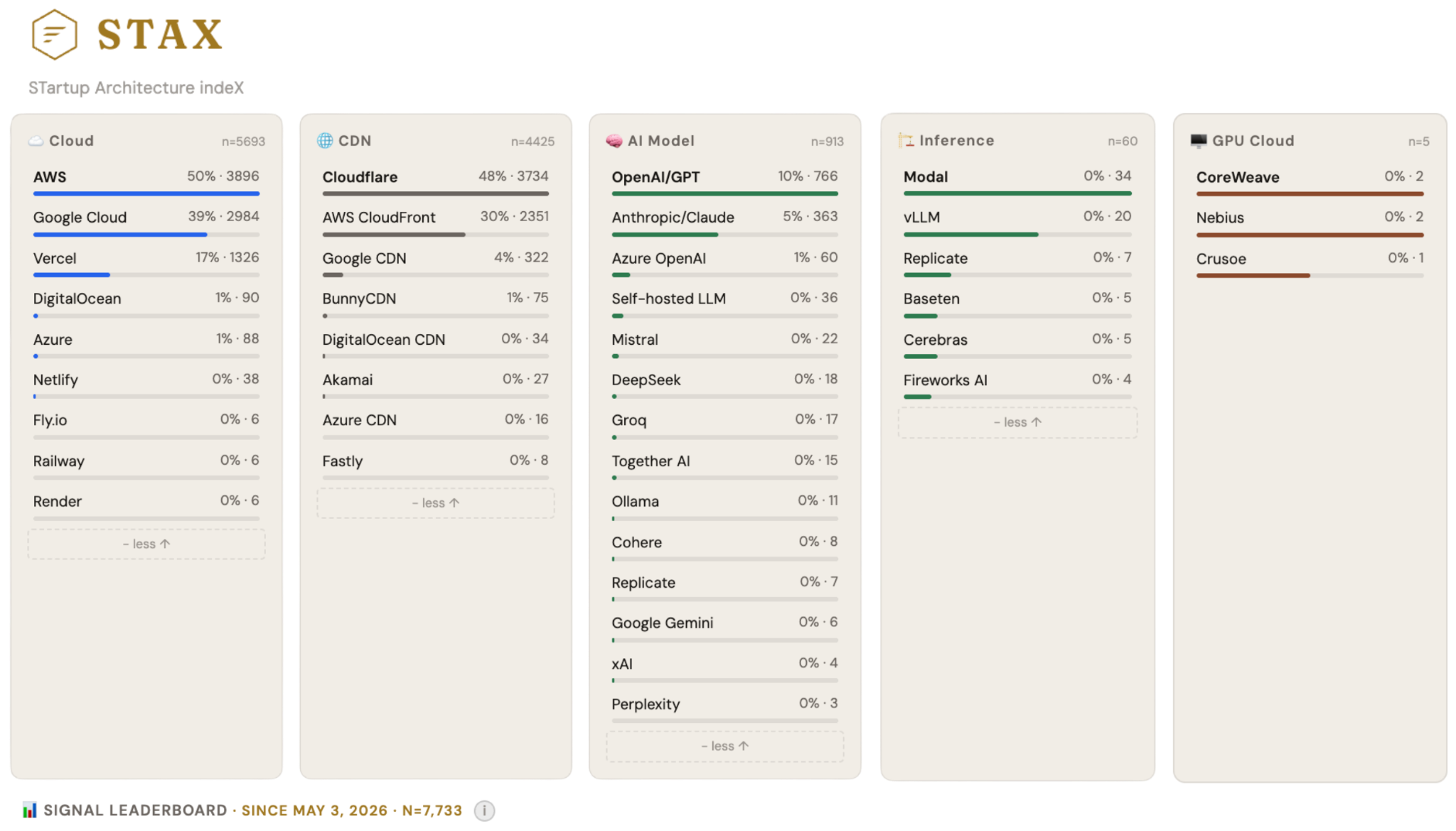
These teams are on platforms like DigitalOcean, Cloudflare, Together AI, Fireworks AI, Baseten, and Modal. Based on what we’re tracking across 7K+ companies in STAX (Porch Capital’s intelligence platform): OpenAI/GPT signals show up in 10% of stacks (766 companies); Anthropic/Claude in 5% (363). The detectable inference-layer — Modal, vLLM, Replicate, Baseten, Cerebras — clocks in at roughly 60 companies combined, with GPU Cloud (CoreWeave, Nebius, Crusoe) in fewer than 5. That 10:1 ratio almost certainly understates the middle. API calls leave public fingerprints. Self-hosted models and inference runtimes don’t — they’re inside the stack, invisible from outside. The 60 is a floor.
This isn’t a transient tier. It’s where a lot of teams find their groove. It’s also not one thing. It splits into two approaches that converge on the same customer from different starting points.
Same Destination. Different directions.
These platforms look similar from the outside. Dig in and differences show up.
DigitalOcean, for example, still feels like infrastructure first. GPU instances, layered tooling, Gradient (from its Paperspace acquisition) if you want guardrails. There’s a sense you’re operating an infrastructure system — a nicer one than before, but still an infrastructure system.
Together AI, Fireworks AI, and Baseten start from the model. Pick one, configure it, plug it in. The infrastructure exists but stays polite unless you go looking for it.
They’re circling the same customer from opposite directions. One path: machines first, add convenience and optimization later. The other: inference and tooling first, and then quietly build out the machines underneath.
Either way, the end state is the same. The interesting question is who gets there with better unit economics and more defensible positioning.
M&A is saying what product strategy is showing.
Lightning AI and Voltage Park merged in January, combining Lightning’s platform — built around PyTorch Lightning and used by 400K+ developers — with Voltage Park’s fleet of 35K+ H100, B200, and GB300 GPUs. The combined entity came out valued at over $2.5B with ARR exceeding $500M. The pitch: stop making developers choose between good software and cheap GPUs. Own both, bundle them, compete on the integrated margin.
CoreWeave completed its acquisition of Weights & Biases — reported at around $1.7B — doing the same thing from the infrastructure side. W&B brought training, evaluation, and monitoring tooling; CoreWeave brought (a fuck ton of) compute. The first joint product launch framed it as “metal-to-token observability” — infrastructure and application layer closing the gap.
Cloudflare has been moving in the same direction more quietly. Its acquisition of Replicate gives it a model execution and developer-facing layer on top of its global network — effectively pulling inference closer to the edge and bundling it with the underlying infrastructure.
Now Nebius is acquiring Eigen to add inference optimization on top of its compute layer.
Three deals. Three different starting points. Same destination: own the system that runs models in production end-to-end, not just a piece of it. The specific assets differ. The logic is identical.
Optimizing runtime performance.
Seen through that lens, the Nebius+Eigen deal makes more sense. (And just might explain the 14% Monday stock pop.) Nebius already had compute. Eigen brings inference optimization — software that determines how efficiently a model actually runs on that hardware. Combined, it’s an attempt to own both sides of the cost equation.
That matters because most of the margin destruction in this tier comes from inefficient inference — too many tokens, too much memory, too little batching. For the middle tier, the shift isn’t just about the integrated margin — it’s about the “Token-to-First-Byte” race. (It’s like Time-To-First-Token (TTFT), but different.) If you don’t own the optimization software (Eigen) and the metal (Nebius), you can’t hit the sub-20ms latency required for the next generation of voice-to-voice agents. If Nebius can control that surface, the economics of their platform get structurally better in ways that are hard to replicate by just buying more GPUs.

Worth noting: companies like Makora (disclosure: I am a strategic advisor / have equity) are building platforms that use LLM agents to auto-generate and inject optimized GPU kernels directly into PyTorch workloads. Pure inference efficiency, no hardware bundle required. And the creators of vLLM founded Inferact, with $150M of fresh-out-of-the-oven seed funding at an $800M valuation, co-led by a16z and Lightspeed.
Notably, Inferact raised before shipping an enterprise product. That’s a big bet that the inference runtime layer is a standalone, fundable, category-defining business. Which should tell you that the problem is real enough to support dedicated solutions, even before the infrastructure players try to own it through M&A.
The companies that win this layer won’t be pure infrastructure or pure tooling. They’ll be the ones that consolidate a full system, with enough vertical integration to build a cost advantage nobody else can easily close. The Nebius+Eigen deal is one version of that bet. (I’m long for a reason.)
Where this leaves the market, From the Porch.
A lot of the day-to-day AI work is happening in this middle layer. Products absorbing AI into their core workflows. Teams figuring out what it means to operate these systems over time. Platforms evolving — or merging — to meet them there.
The popular narratives will keep clustering around foundation models and API announcements. Those are easy to measure.
Watch the layer in between. It doesn’t announce itself loudly. It just keeps expanding.

Disclosures: I maintain positions in NBIS, CRWV, and NVDA. I am an equity compensated strategic advisor to Makora. I am an LP in an SPV that owns shares of Crusoe. I use AI liberally to help write posts, though the theses, believe it or not, are actually my own.