
The Machine-Native Trade
Part 2: From infrastructure to intelligence — where agentic AI starts paying dividends

In The Machine-Native Network (part one of this series), we explored how AI is shifting from the prompts, chatbots, copilots, and GenAI tools of today to agentic AI: machines and code that plan, negotiate, and act on their own — forcing the infrastructure beneath them to evolve. Builders, this is your early innings. Investors, this is your signal. The compute scaffolding we built for humans is dissolving, and the network is reorganizing itself around power, cost, proximity, and autonomy. Companies that align with tomorrow’s faster, closer, smarter, cooler physics are the ones to be repriced. LFG.

🧭 Note from The Porch: this piece is dense; you’ll survive it. But before we dive down the rabbit hole, here’s the quick hit: the Machine-Native Trade in one glance.
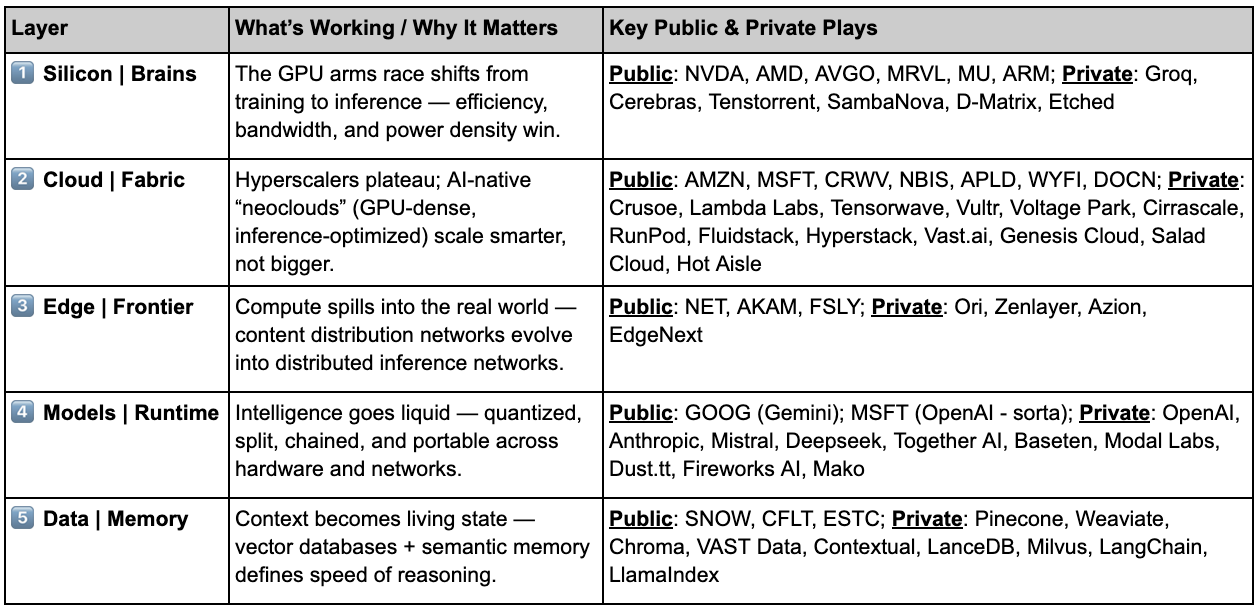
Cheat mode unlocked. Now let’s start where every machine’s mind begins — in silicon.

Layer 1 – Silicon | The Brains
The GPU race that once fueled training is gravitating toward inference. In 2024, spend on inference exceeded 50% of total AI spend from ~25% in 2019; and inference now drives roughly half of Nvidia’s datacenter revenue. Agentic AI will accelerate this shift as it thinks continuously and runs live feedback loops that demand chips built for speed and power efficiency, not brute force. Nvidia (NVDA) still dominates, but MI300s and upcoming MI400s from AMD (AMD) are already in test pipelines with OpenAI and Oracle. “Hidden” underneath, chips from Broadcom (AVGO) and Marvell (MRVL) facilitate interconnect; Micron (MU) makes AI-critical High-Bandwidth Memory (HBM); Arm (ARM) and Qualcomm (QCOM) are sneaking chips into edge devices; and TSMC (TSM) still manufactures almost everything.
The shift to inference also opens the door for a new class of “neochips” optimized for low-latency, high-throughput inference rather than brute-force training. Groq makes its own chips (but doesn’t sell them), deploys them in data centers and colo facilities (but doesn’t rent them out by the hour), and sells access to models (that they optimize) by the token. Others — e.g., Cerebras, Tenstorrent, SambaNova, D-Matrix, Etched — take different routes, packaging inference IP into vertically integrated systems that skirt the CUDA moat.

Layer 2 – Cloud | The Fabric
Smarter chips needed better homes. Hyperscalers accommodated, but their legacy architecture holds them back. That’s why neoclouds like CoreWeave (CRWV), Nebius (NBIS), Applied Digital (APLD), WhiteFiber (WYFI), and DigitalOcean (DOCN) (via Paperspace) built datacenters natively for AI so that training and inference runs cheaper, faster, and cooler. Since CoreWeave’s March IPO, our mini GPU cloud index is up about 3x on average. (The Year of the (GPU) Cloud indeed.)
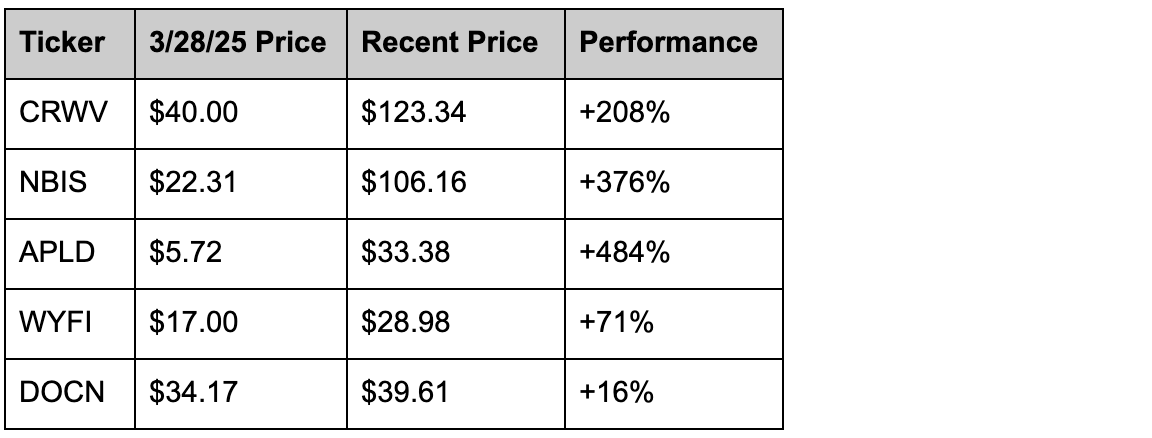
Including private markets grows the list: Crusoe (supposedly raising at ~$10B now) and Lambda ($4-5B valuation); not to mention Tensorwave, Vultr, Voltage Park, Cirrascale, RunPod, Fluidstack, Hyperstack, Vast.ai, Genesis Cloud, Salad Cloud, Hot Aisle (to name a few). These are AI-native clouds built for inference and agentic workloads that benefit from superior physics and (consequent) superior economics.
But this story doesn’t end in the data center. When agents begin making decisions on their own, intelligence moves out of the cloud closer to the world.

Layer 3 – Edge | The Frontier
As agents start negotiating their own compute, they can’t rely on static data-center logic. They need to choose the right silicon in the right place at the right moment to balance latency, power, and cost in real time. That’s what pulls intelligence to the edge.
Apple has spent years trying to push true on-device (Apple I)ntelligence, but Siri still falls back to the cloud (and, well, still kinda sucks). Enterprises, meanwhile, are adopting hybrid setups that keep sensitive or high-frequency workloads on-prem while jumping to the cloud for everything else. The machine-native shift forces those worlds to meet in the middle.
In the public markets, legacy CDNs — Cloudflare (NET), Akamai (AKAM), and Fastly (FSLY) — are re-architecting from content delivery to distributed inference. Cloudflare has been plenty vocal; and Akamai recently posted an Edge AI product-management role. Meanwhile, new private players like Ori, Zenlayer, Azion, and EdgeNext are building infra to serve machine workloads that move, talk, and adapt. Even NCOTB (New Cloud On The Block) Crusoe recently posted an edge computing PM role.
The edge is where agents start to self-optimize — allocating just enough compute to think, act, and coordinate on their own. It’s where the Internet stops serving people and starts serving machines. (For more on this idea, see AI’s Next Battleground: The Edge.)

Layer 4 – Models | The Runtime
The era of giant, isolated “big brains in the cloud” is morphing as models are quantized, distilled, split, and chained (tl;dr: models shrink) so they can run efficiently across any layer of compute: cloud, edge, or device. OpenAI’s GPT-5 (still) leads with multimodal reasoning and persistent context; Google’s Gemini 2.5 balances scale with speed and adaptability; and Anthropic’s Claude Sonnet 4.5 and Opus 4.1 push deeper into agentic, long-horizon reasoning and code execution.
But hey, fellas, size (does) matter; it’s just not about how big the model is anymore, it’s how you route it. And in the agentic, machine-native world, smaller can be smarter. Mistral Small 3.1 pushes efficient multimodal reasoning inside Vertex AI’s Model Garden. DeepSeek v3 optimizes for structured code + vision tasks. And LLaMA 3 and its open derivatives remain the substrate many runtimes build upon.
As the models get smaller (and more abundant), they need a way to talk to each other; otherwise: too many models on the dancefloor.🕺 Anthropic’s Model Context Protocol (MCP) is a new standard that does just that – it lets models exchange context, tools, and memory the way web servers once shared data over HTTP. It’s how Claude, Gemini, and GPT-x can coordinate with third-party or open models without human orchestration. A few other companies are already building this coordination layer — Alpic.ai, Fixie.ai, and CrewAI are wiring the workflows between autonomous agents — early prototypes of what might one day become the ServiceNow or Zapier of an agentic world.
Just below the models sits an emerging runtime stack. Together AI, Baseten, Modal Labs, and Dust.tt are adaptive runtime and orchestration layers that let models chain, specialize, and route logic across heterogeneous hardware. Fireworks AI powers high-performance inference, context routing, and model-serving optimization. And Mako is an LLM that writes GPU kernel code, dynamically re-optimizing models for whatever silicon it lands on.
Models think, but memory makes them useful; and we need new data architectures for this new machine-native world.

Layer 5 – Data & Context | The Memory
The new data layer isn’t a warehouse; it’s a living stream that syncs continuously with the agents using it. Context stops being something retrieved and starts being something maintained. Public players like Snowflake (SNOW), Confluent (CFLT), and Elastic (ESTC) are evolving from analytics platforms into context engines, feeding real-time data into autonomous systems.
Below the public radar, a new architecture of vector, semantic, and memory stores is taking shape. Pinecone, Weaviate, and Chroma anchor vector retrieval — the memory layer for models and agents that need fast, context-aware recall. VAST Data turns raw storage into high-performance, GPU-aware infrastructure, collapsing the boundary between storage, memory, and compute. Contextual, LanceDB, and Milvus are emerging as “living databases” that sync with agents in real time. And retrieval frameworks like LangChain and LlamaIndex still matter — not because they’re “apps,” but because they define how context becomes portable across agents and systems.

The Machine-Native Trade – Execution
Every layer of the stack — chips, clouds, edge, models, data + memory — is learning to think. The physics still matter (power, cost, latency), but the economics now revolve around coordination, context, and cognition. This isn’t the end of the GPU trade; it’s the beginning of machine-native infrastructure where compute stops waiting for humans and starts optimizing for itself. And the capital markets haven’t fully priced that in… yet.
Disclosures (so I don’t go to prison)
I currently own shares of Nvidia (NVDA) and CoreWeave (CRWV).I’m an investor, via SPVs, in Groq and Crusoe.I’m also a strategic advisor to Mako — which means I occasionally help teach machines to think faster than humans do.At the time of publishing, I’m not trading any of the other public companies mentioned, but I could be in the future, because that’s how markets work.Likewise, I could at any point become an advisor to or investor in any of the private companies referenced here, though I’m not today (yet). Unless, of course, one of them wants to call me first.This post is not financial advice, nor should it be confused with NFA, DYOR, YOLO, or FOMO. It’s simply TFTP — Thoughts From The Porch.
This piece really made me think about agentic AI. What if these machines start autonomously redesigning the network infrastructure for pure efficiency, far beyound our current scope? So insightful.
Your point about Broadcom "facilitating interconnect" deserves more spotlight than the "hidden underneath" framing suggests. As agentic AI distributes workloads across cloud, edge, and device (your Layer 2-3), the bottleneck shifts from compute to communication. Broadcom's networking switches and custom ASICs become the nervous system of this machine-native world. What I find particuarly compelling is the timing - just as models get smaller and more distributed (your Layer 4 argument), the demand for high-bandwidth, low-latency interconnect explodes. Most investors are still fixated on GPU wars while missing that the real constraint for agentic AI at scale is how fast different chips can talk to each other. Great piece!