
Fastly’s Hidden Edge
3Q25: nice print; bigger option.

Fastly’s stock jumped 43% last week to $11.56, and everyone suddenly remembered it still exists. Its most recent close was $11.93 per share, but this could be a $25-30 stock if management realizes it’s been sitting on an AI option the whole time. With a cheap GPU retrofit, this goes from a boring CDN turnaround story to a fast-growth, more profitable AI-infrastructure play.

I wrote something similar about DigitalOcean this week — another “unsexy infra” name with an underappreciated AI lever. Fastly’s edge footprint could tell a similar story.
The third quarter wasn’t a miracle. It was diligent work, a margin print, a security upsell, and a reminder that the bones of this network were always better than its multiple. And while the Street’s just noticing that, Porch has been looking at something much bigger.
Buried inside this CDN may be a ready-made edge-AI infrastructure company. The kind that doesn’t need to spend billions building new data centers — “just” retrofit the infra it already has.
Fastly’s 80-100 global PoPs are dense, modern, and power-provisioned. They were built to deliver content milliseconds faster; with the right (cooler, cheaper, lower power) GPUs, they could deliver intelligence just as fast. That’s the play. Whether it’s management, an activist, or a private buyer who acts first, the opportunity is the same: turn this from a CDN recovery story into an edge-inference AI growth platform. Most of the hardware is there. The economics work (at least in my head). The Street just hasn’t modeled it yet.
The real story isn’t a turnaround. It’s a retrofit.
Back in August, I wrote AI’s Next Battleground: The Edge, about how inference moves closer to users and cheaper for providers, how latency flips from nuisance to deal-breaker, and how the edge becomes AI’s next competitive front.

That wasn’t an abstract essay. It was the public prelude to a thesis I’m still pursuing: that parts of Fastly’s edge footprint could be repurposed for AI inference, not just content delivery.
This quarter supports that potential.
Fastly’s Security segment grew 30% year-over-year, pushing total revenue up 15% and gross margin north of 63% — proof of concept for layering higher-value services on top of the edge. Security was the first. Inference could be next. Moreover, cash flow turned positive. That matters (a lot) because it means the company (or an acquirer) can leverage some of its own FCF to fund a transformation.
Oops, we built an edge-AI network.
Most think of Fastly as a tired, low growth, commodity CDN. (And most may be right, for now.) But the network it already runs could also be one of the cheapest global footprints for AI inference. And that is most certainly not priced in.

Fastly’s 80-100 PoPs are already powered, cooled, and peered in the right metros. With a modest retrofit, they could become the world’s most capital-efficient GPU edge — a distributed inference layer living closer to people, apps, and data than the hyperscalers and neoclouds can reach.
The math isn’t (pure) fantasy; it’s infrastructure arithmetic — directional, modeled, and very possibly wrong in the details (but right in spirit).
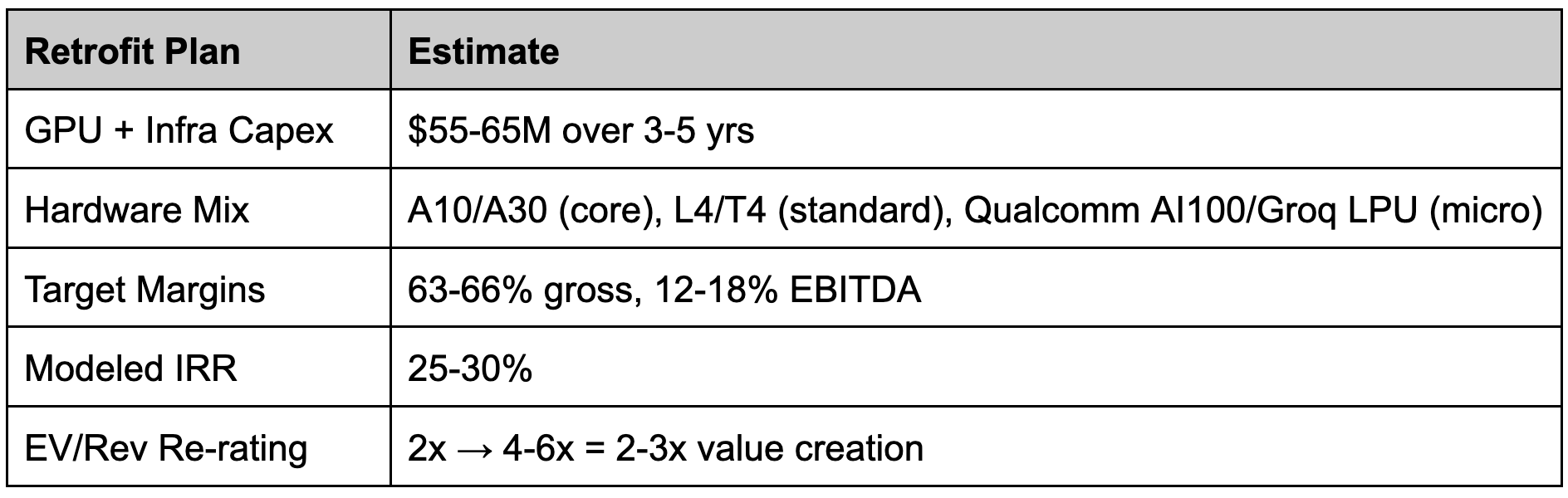
Re-creating that footprint from scratch could cost $3-4B, based on ~80-100 PoPs x $30-50 million per site for real estate, colo, power, cooling, interconnect, racks, servers, and a cocktail of hubris and regret. By contrast, Fastly could do it for less than the price of a single hyperscaler region and with geographic reach no wicked-hot AI startup could replicate overnight. That’s not an incremental upgrade. It’s a category shift from content delivery network to edge AI inference network.
The $8B edge option.
The global AI inference market was already almost $100B in 2024 and is projected to grow to >$250B by 2030 (according to Grand View Research when I asked ChatGPT to find numbers to fit my narrative.) According to another Grand View Research report (which I found the same way), the global edge-AI market was ~$20B in 2024 and could exceed $65B by 2030 (~20% CAGR). My modeled assumption says that “edge-inference share” could push toward ~$80B by 2028 (30-40% CAGR) with an inference shift from centralized clouds to distributed edge systems. Fastly obviously can’t and doesn’t need to capture the whole market. Retrofitting its existing PoPs could plausibly unlock just 5-10% of global edge-inference demand — a $4-8B incremental opportunity layered on top of its ~$600M core business.

At that scale, a ~2x revenue multiple becomes 4-6x, revenue growth accelerates, EBITDA turns (more) positive, and a “commodity CDN” starts screening as a capital-efficient edge-AI infrastructure play. The network already exists; the market (and possibly management) just hasn’t found it yet.
Why customers want this. (Spoiler: 90% cheaper, 5x faster, and 100% regulator-proof.)
Customers don’t care about Fastly’s history (which, until last week, was, well, “rough.”) They care that Fastly could run most inference workloads 75-90% cheaper than hyperscalers and ~50% cheaper than neoclouds.
Not for all AI, of course — nobody’s training 70B-parameter models on the edge (yet). But for up to ~70% of inference workloads (by 2030) that are lightweight, latency-sensitive, and geographically distributed — the kind behind personalization, content moderation, and retrieval-augmented chat — the economics flip hard in Fastly’s favor. Running inference on hyperscalers and neoclouds is like paying full freight for compute, bandwidth, and air conditioning on every single prompt. But not every prompt needs an Nvidia B200 answering from a data center a million miles away — cooled by liquid nitrogen and shareholder tears.
💰 The cost. (Warning: math incoming.)
A moderate model (3K tokens per request, mix of RAG and generation) serving 1M prompts a day costs ~$600K/month on AWS — about $0.04 per prompt. Running the same workload on a neocloud like CoreWeave or Lambda drops that to about $300K/month ($0.02 per prompt). On Fastly’s existing PoPs, using L4 or A10-class GPUs amortized over 3-5 years, the number falls to $100-200K/month; i.e., 75-90% cheaper than hyperscalers and ~50% cheaper than neoclouds.
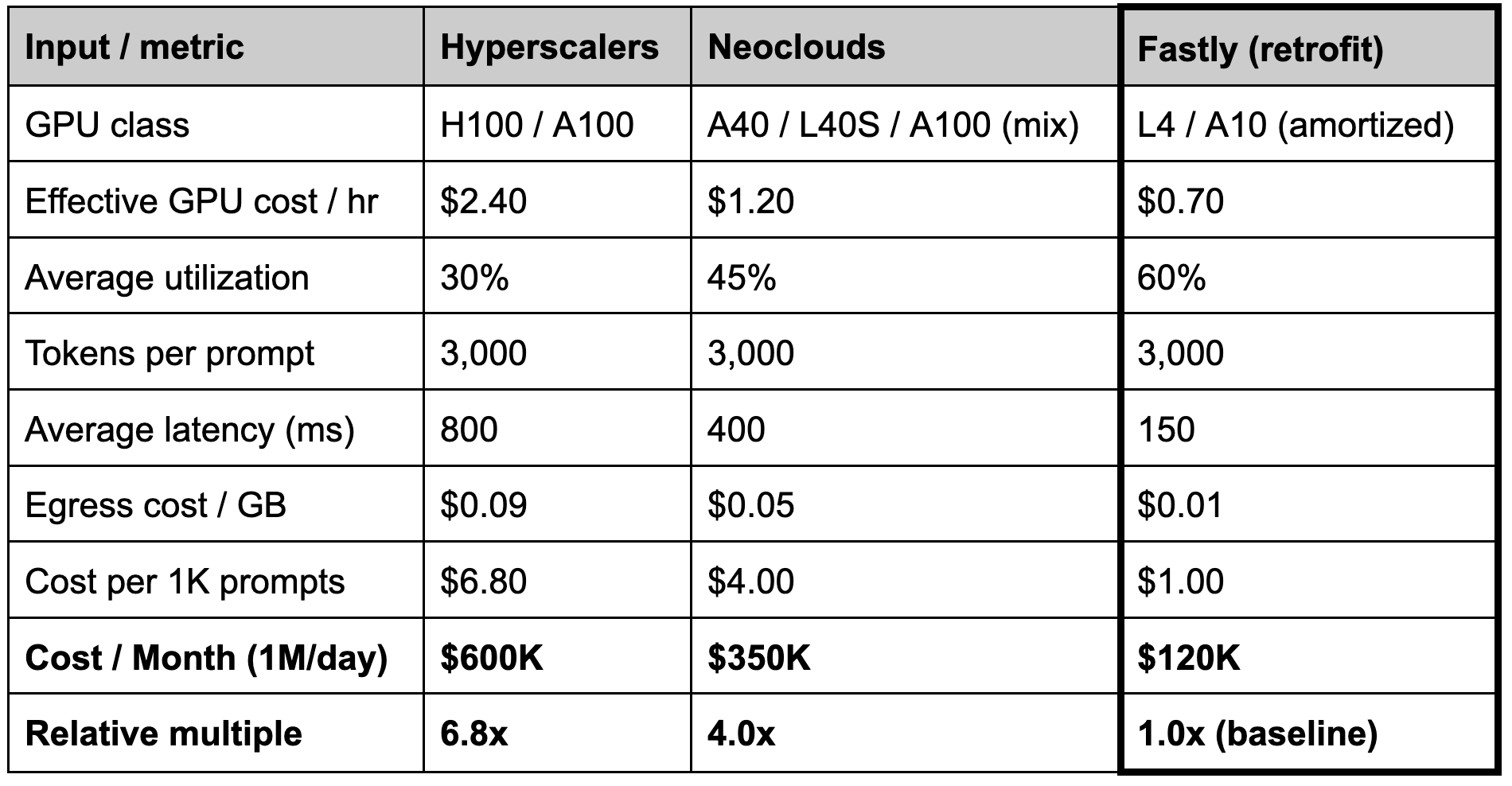
How? Hyperscalers burn H100s (and up, if they can get their hands on better) on inference because that’s what they’ve got. Neoclouds right-size with L40s and A10s, saving the H100s+ for training. Fastly can go a step further using L4s in the racks, interconnect, and (air) cooling it already owns. Its (“new”) GPUs won’t need liquid cooling and can run longer — edge inference sustains roughly 60% utilization versus 30-40% in centralized clouds, and there’s no $0.09/GB egress toll every time a token leaves the building. No new regions. No liquid cooling. No billion-dollar data centers. Just GPUs where the traffic already lives.
✈️ The latency. (Advantage: edge.)
Cost isn’t the only variable in Fastly’s favor — there’s also the speed kicker. When inference moves closer to users, milliseconds change from rounding errors to business outcomes. (Kinda like why CDNs launched circa Y2K in the first place.) Sure, for something like a ChatGPT prompt, network latency is a rounding error next to GPU compute time — the bottleneck is the silicon, not the distance. But that ratio flips for fast-growing edge-AI workloads like real-time personalization, content moderation, gaming logic, voice and vision agents, industrial automation, autonomous systems, healthcare, and any app where “real-time” actually means real time. For those use cases, every millisecond matters — and shaving 400–600ms off round-trip latency isn’t optimization; it’s enablement.
Fastly’s existing PoPs already sit within 10-30 ms of most major population centers. Add low-power GPUs (L4s, A10s, Groq LPUs — take your pick), and those same edge nodes can execute inference locally — roughly 3-5x faster than regional cloud zones and up to 10x faster than cross-continent calls to centralized GPU clusters.

In other words: hyperscalers may own the geography, but they don’t compute there. Fastly could — if it remembers that CDNs were just proto-AI edges all along.
🌎 The data sovereignty. (Regulators hate how good this is.)
The third advantage isn’t about speed or cost — it’s about where your data sleeps at night. With AI inference, every cross-border hop can trigger a compliance migraine. Fastly’s edge footprint already sits inside most major data regimes — US, EU, UK, Canada, Japan, Australia — with local colocation, power, and network presence. If inference happens there, it stays there.
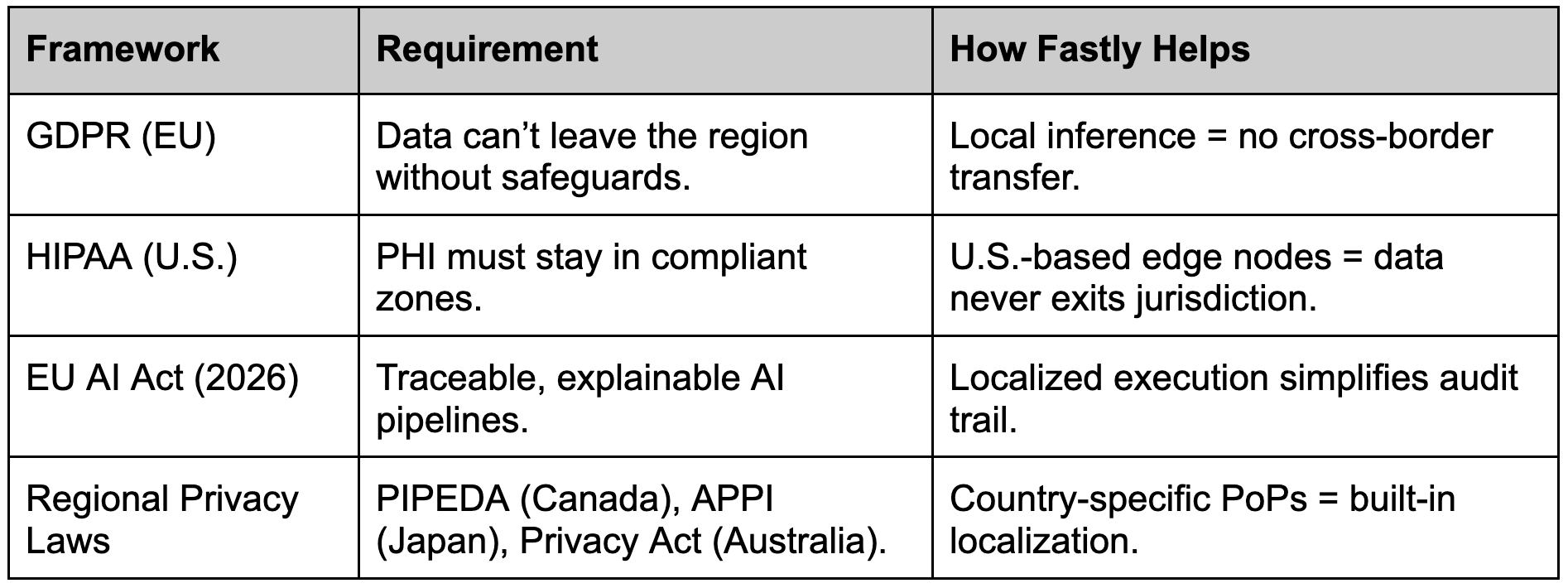
That’s data sovereignty by topology — compliance baked into geography, not contracts. And if sovereignty, speed, and cost all align at the same edge, that’s not just compliance — that’s competitive advantage.
From CDN to AI infra — the capital-efficient way.
The beauty of this isn’t in some moon-shot rebuild (even if it still qualifies as a pipe dream); it’s in the reuse. CDN traffic yields ~55% gross margins. Edge inference? ~75%. That’s a 500-1,000 bps lift on blended gross (and likely EBITDA) margins — plus faster revenue growth because inference isn’t an add-on — it’s a new business hiding in the old one. Same pipes, new payload, better margins, faster growth, higher multiple.
And here’s the kicker: with roughly $18M of free cash flow last quarter and $343M in cash that offsets some of the manageable converts due 2026, the company could fund much of that retrofit itself — or an acquirer could. Either way, the math works.
This isn’t (just) a turnaround story. It’s a capital-efficient edge-AI inference option — the kind of pivot Wall Street almost never prices in until it’s already happened.
View from the Porch.
The Street saw the margin beat, the execution, the attach rates; Porch sees ~100 PoPs waiting to light up with GPUs. When those nodes stop just caching content and start running inference, Fastly isn’t a CDN multiple anymore. It’s an Edge-AI multiple — with economics built for the next cycle, not the last. If that happens — if even a fraction of this retrofit plays out — the stock isn’t an $11 story. It’s a $25-30 re-rate on optionality alone, and higher if management actually builds it.
The edg infrastructure angle is really underappreciated here. Most people see Fastly as a struggling CDN but the existing PoP footprint could be a massive cost advantag for inference workloads. The data sovereignty point is particularly strong with all the regulatory presure around cross-border data flows. If they can retrofit with L4 or A10 GPUs without major capex, the margin expansion story becomes compeling. The real question is whether managment has the vision to pivot or if it takes an activist to unlock this. Either way, $11 looks cheap if even a fraction of this edge-AI thesis plays out.