
Fastly’s Hidden Edge Is Showing.
And It’s powered by CPUs.

AI tailwinds in 4Q25 gave Fastly its second beat-and-raise quarter in a row and a well-earned 35% aftermarket pop last night. Revenue, EBIT, EBITDA, FCF — nearly every acronym that matters — beat expectations, and management guided above the street for 1Q26 and this whole year. And the cherry on top is a CPU, not a GPU.

The dominant AI narrative for the last two years has been GPUs win, everything else is noise. (Just ask my wife; she banned the term “GPU” from our house because I haven’t stopped talking about it.) But that story is evolving. SemiAnalysis published “CPUs Are Back…” this week arguing that AI workloads are more heterogeneous than the market (and the Porch) narrative suggests. As systems become more agentic and multi-step, CPUs increasingly handle orchestration, control flow, data sharding, indexing, routing, and context management. That’s the layer Fastly already monetizes with Compute@Edge, which helps explain why the AI tailwind showed up — even without any GPUs.
GPUs execute tensor math.
CPUs decide what tensor math to execute, when, and why.As AI systems get more complex, that CPU function becomes more important. This matters for Fastly and other CPU compute platforms because many like Fastly already own programmable CPUs in the request path.
The hidden edge, revisited.
When I wrote Fastly’s Hidden Edge in November after the 3Q25 beat-and-raise (and, truth be told, after circulating an investment memo last summer proposing to take Fastly private), the thesis was infrastructure optionality. Fastly operates a relatively small number of modern, adequately-powered, programmable POPs. If inference workloads themselves moved outward from hyperscaler and neocloud clusters, Fastly’s footprint could matter more than investors realized. It was a cost and latency argument.

Then came models prompting models – the agentic layer that is compounding inference workloads. Rather than a single call or request or prompt or whatever you’d like to call it, agents branch, retry, validate, and call multiple models per user action. The result: inference growth goes from linear (more AI users prompting models) to exponential (those models prompting other models repeatedly and constantly).
So… did I call it? Sort of. Just not in the way I originally thought (or at least not yet). My thesis was that distributing inference workloads to edge infrastructure would bring down costs and mitigate the strain on energy requirements. More inference calls means:
More routing decisions.
More fallback logic.
More rate limiting.
More policy enforcement.
More API security filtering.
More bot mitigation.
More licensing enforcement.
What I got wrong (or, worse, didn’t realize at all) was compounding inference’s impact on orchestration complexity and, well, where that orchestration happens. Spoiler alert: that orchestration happens on CPUs, not GPUs. And in evolving architectures, some of that happens at the edge.
4Q25’s AI tailwind.
On the call, Fastly management noted:
Increasing agentic traffic.
Fastly’s ability to distinguish machine-to-machine flows in telemetry.
Media customers shifting from blocking AI crawlers to optimizing for them.
Compute@Edge being used for inference and AI-related workloads.
AI bot mitigation becoming a tangible product driver.
Fastly is already processing AI-related orchestration on CPUs. No GPUs though. Oops. Either way, the stock popped, so I’ll take the win.

This is becoming a pattern for me. My DigitalOcean GPU thesis last year suggested undervalued GPU optionality. The stock popped thirteen days later, but the catalyst wasn’t GPUs. Meh, I’ll take the win. Fastly feels similar. But I’m slightly less wrong this time because AI was indeed the catalyst; just, the increasingly critical mechanism is CPU orchestration, rather than edge (GPU) hosted inference. Still works for my core thesis, so I’ll take the back-to-back W’s.
An orchestration layer around inference.
A realistic next-gen AI architecture may not require GPUs in every POP. To explain, let’s look at how a single edge orchestrated inference call could work:
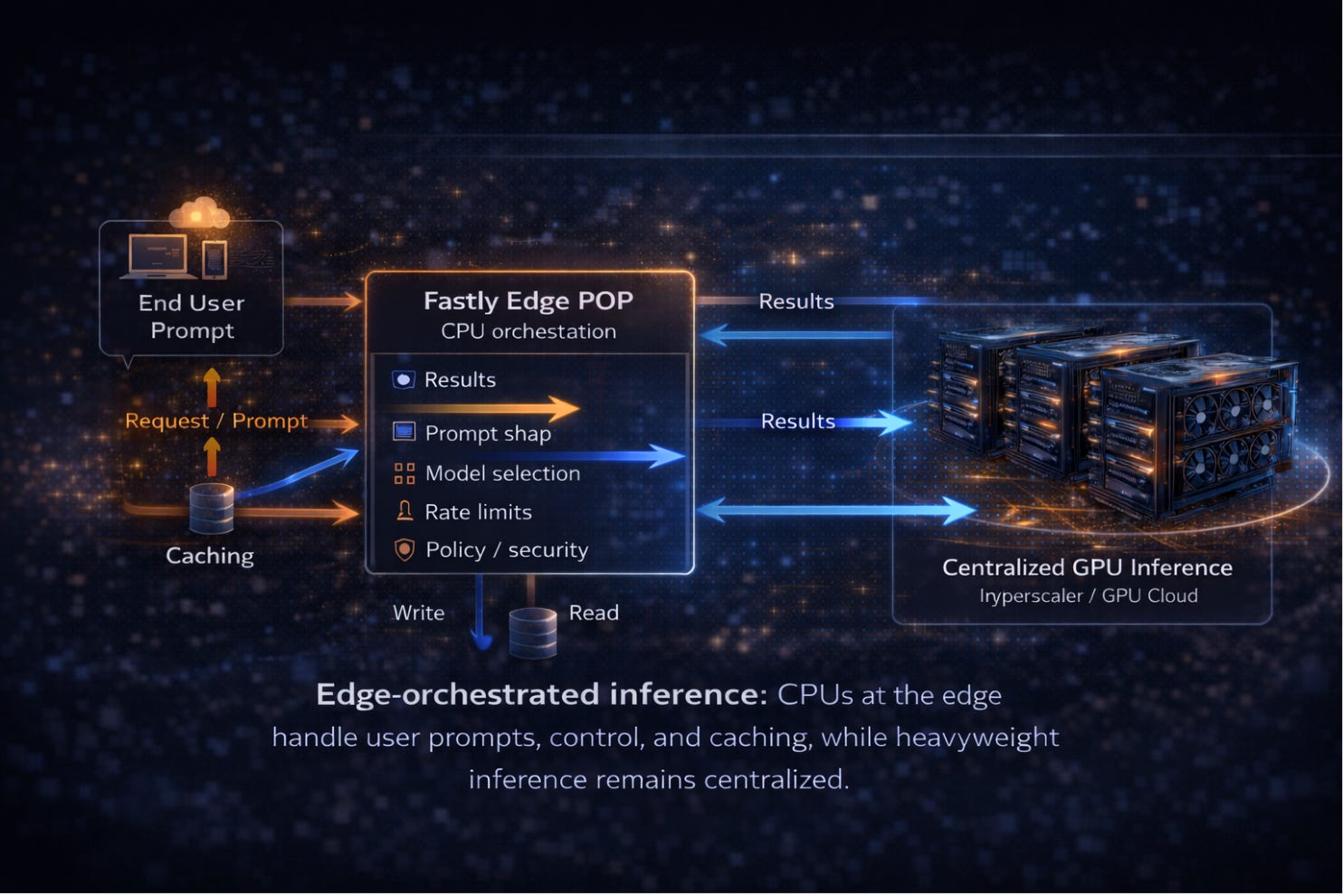
A request hits a Fastly POP.
The edge CPU handles authentication, prompt shaping, model selection, rate limits, and policy enforcement.
Heavy inference runs in centralized GPU clusters called by the edge hosted CPU.
Results stream back through the edge, where caching and enforcement happen.
If inference calls like the aforementioned one multiply exponentially, orchestration requirements multiply (exponentially). Which means that demand for layers that manage orchestration, like Fastly’s Compute@Edge, should multiply (exponentially). From that lens, Fastly’s position creates a narrow but meaningful set of outcomes (not all equally likely, and not all near-term).
So what does this actually mean for Fastly?
In practice, this is where things branch. Choose your own adventure. (Warning: not all of them end well.)
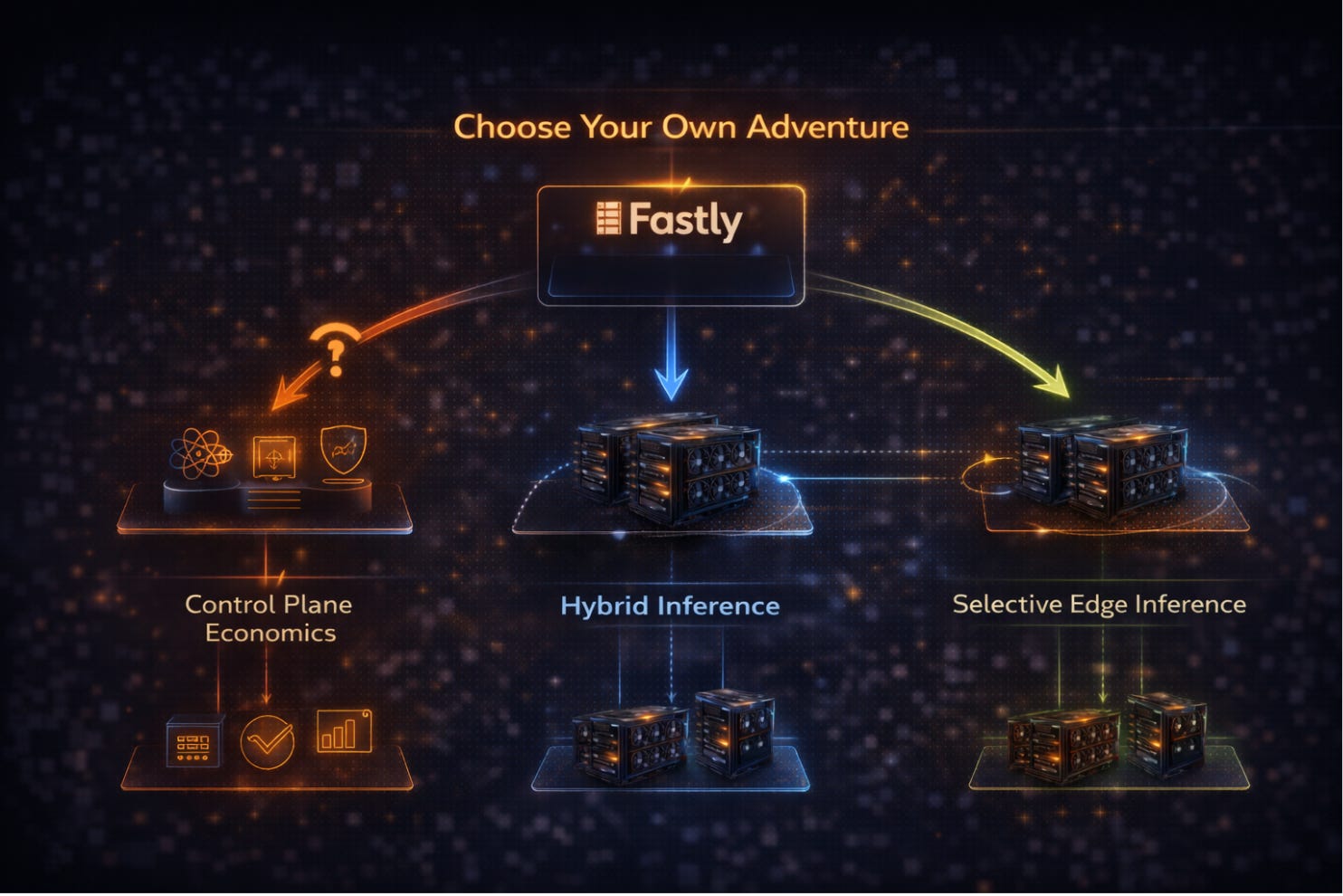
Near-term (and already visible): control plane economics. Fastly avoids owning GPUs and doubles down on being the AI control plane: model routing, telemetry, policy enforcement, agent-aware API security, licensing controls. Fastly sits in front of inference, but not in it. This aligns with existing products, existing customers, and existing capex discipline. If this is happening, it should show up in Compute@Edge growth, AI-related RPO, and more explicit AI gateway language.
Medium-term: hybrid inference architectures. GPUs remain centralized (outside Fastly) in hyperscalers and neoclouds, while Fastly’s edge handles orchestration and streaming inside the inference path. This requires partnerships more than hardware, and the signal would be integrated endpoints rather than owned infrastructure.
Longer-term: selective edge inference. Add low-power inference in a handful of cost- and latency-sensitive locations; i.e., my original Fastly proposal. This has higher upside, higher risk, and likely only justified for specific workloads. This would show up clearly in capex and hardware disclosures.
Fastly doesn’t need to become Nvidia or AWS or CoreWeave to participate meaningfully in AI economics. Owning the programmable control plane may be sufficient – and, importantly, measurable. If that control plane continues to matter more as inference compounds, these become credible paths for growth and valuation to follow.
How to tell which path Fastly is taking.
If this moves beyond architectural optionality, it should show up in observable signals – and which signals show up matters.
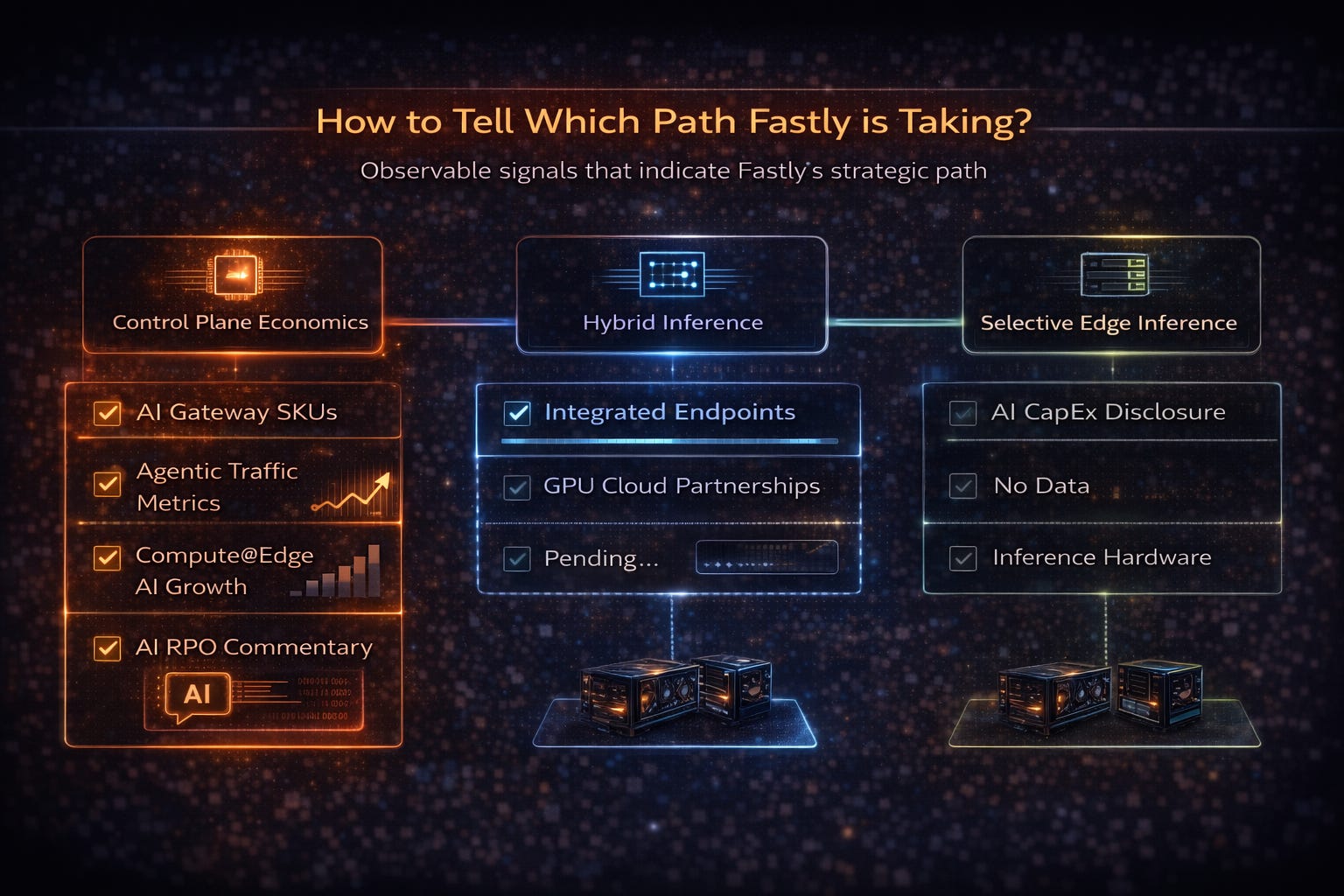
Control plane economics (already visible):
Explicit AI gateway or orchestration SKUs emerging.
Clear metrics on agentic traffic growth reported.
Compute@Edge growth increasingly tied directly to AI workloads.
AI-driven RPO commentary.
Hybrid inference architectures:
Integrated inference endpoints abstracting multiple GPU providers.
Commercial GPU cloud partnerships, not just integrations.
Selective edge inference:
More detailed capex language tied specifically to AI infrastructure.
Hardware disclosures that point to inference acceleration, not just capacity expansion.
Until then, Fastly remains a CDN and security turnaround story with AI tailwinds. The difference now is that those tailwinds are measurable.
TLDR… From the Porch.
My original hidden edge thesis was about infrastructure positioning.
My agentic AI thesis was about compounding inference.
CPUs are regaining importance as orchestration complexity rises.
Fastly is already monetizing programmable CPUs in the request path.
The stock popped on a beat and raise.
The more interesting question is whether the control plane of the AI internet is quietly becoming more valuable than the market assumes. If that happens, I will happily admit that I was right for slightly evolving (i.e., wrong) reasons. And I will absolutely take the win.